



BLOG
弊社英語ブログのうち、いくつかを日本語翻訳しています。英語ブログはこちら

プロシージャルサウンドで
メタバースでも没入感のあるサウンド体験を
一般的にメタバースやMR(複合現実)では、没入感を高めるため、サウンド側でも高度にインタラクティブな表現が求められ、従来のサンプルベース(音源素材)の効果音演出では、その実現にあまり適しているとは言えません。
今回は、メタバースのような新たなデジタル体験が、サウンド演出周りで抱えている課題と、プロシージャルサウンドがそれらの課題を解決する最良のソリューションであることを説明していきます。
音の空間化についてはすでに多くの研究がなされていますが、音の生成(合成)自体はまだ初期段階にあり、あまり言及されていません。プロシージャルサウンドは、(事前に録音されたサンプルを使用する代わりに)モデルと一連のパラメーターに基づいてリアルタイムに音が生成されるため、3Dオブジェクトのレンダリングが、静止画よりも没入型環境を作り出すのに遥かに柔軟であるのと同じで、多くの利点があります。
コンテンツの爆発的増加
たとえば限られたシーンでも、没入型体験を実現するためには、膨大な数のサウンドコンテンツが必要になります。
AVAR 2022のプロシージャルサウンドパネルで、Meta社のScott Selfon氏は、サウンドデザインチームが、卓球ゲーム(球がテーブルや壁などにぶつかる音)のシミュレーションを満足のいくものにするのに、作成が必要になるサウンド数がいくつになるかの実験調査についてプレゼンし、その結果、250個の音源が必要になるとしています。
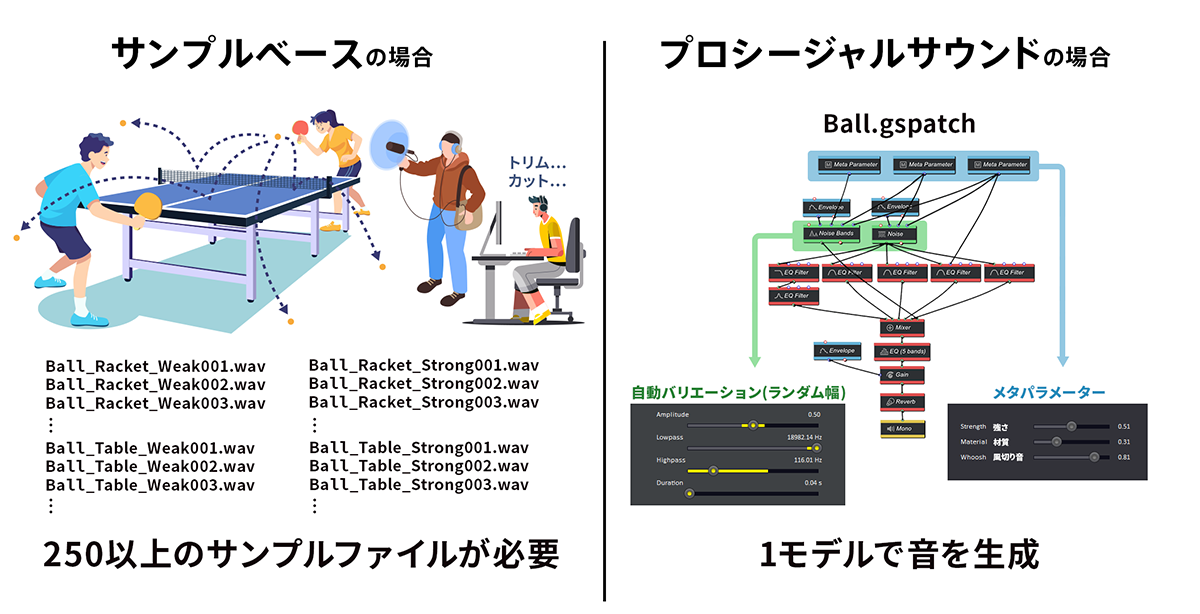
一方でプロシージャルサウンドを使えば、サウンドモデルの設定を調整し、リアルタイムな(物理的に情報が得られる)入力パラメーターをいじるだけで、わずかなサウンドモデルで多くの効果音を都度生成できます。
新たにサウンド素材を調達したり、不足しているフォーリー音を録音したり、プロジェクトのマイナーな変更ごとに既存のサンプルを編集したりする必要がないため、時間と費用を大幅に節約できます。
バリエーション
様々な音が必要となるだけでなく、音の繰り返しを避け、デジタル空間での没入感を壊さないためには、サウンドのバリエーションが必要です。
プロシージャルサウンドモデルでは、パラメーターをわずかにランダム化することで、サウンドバリエーションを自動的に生成できます。たとえば足音、風切り音、銃声などは、サウンドが再生される度にわずかに異なることで、より没入感が増すでしょう。

一方サンプルベースのサウンドシステムでは、サウンド自体の生成は制御できず、音量の増減やフィルターなどのポストプロセスのみでしかバリエーションを作り出せないため、非常に制限がかかってしまいます。
より高いインタラクティブ性
複合現実やメタバースでは、ユーザーはスティックを曲げたり、壊したり、表面を叩いたりと、インタラクティブなオブジェクト操作ができます。
上記の通り、従来のサンプルベースでは音の生成を制御できないため、音をわずかに変えるしかできません。

プロシージャルサウンドモデルは、モデル設定と入力パラメーターの両方を調整することで、より高いレベルのインタラクティブ性を可能にします。よって、物理ベースのインタラクションの場合のように、様々な励起信号として機能することでしょう(たとえば上の動画例では、ゲーム内の物理発生シグナル)。
プロシージャルモデルでは、プレイヤーのアクションが続く限り、繰り返しではない音声が都度生成されます。
通常、サンプルベースのシステムで同じことを行うには、録音された音をタイムストレッチするか(その際サウンド品質は劣化するでしょう)、ループによる繰り返しといった手段に限定されます。
メモリフットプリントの縮小
オープンワールドでは、考えられるすべてのシナリオをカバーするため、大量のサンプルが必要になります(実際、何でも起こり得るARの場合、さらに膨れ上がるでしょう)。
プロシージャルサウンドでは、波形データではなくモデルのパラメーターのみを保存すればいいため、必要なメモリとディスクフットプリントは、サンプル手法と比べて桁違いに小さくなります。これは、特にモバイルプラットフォームを扱う場合、大きなメリットとなります。
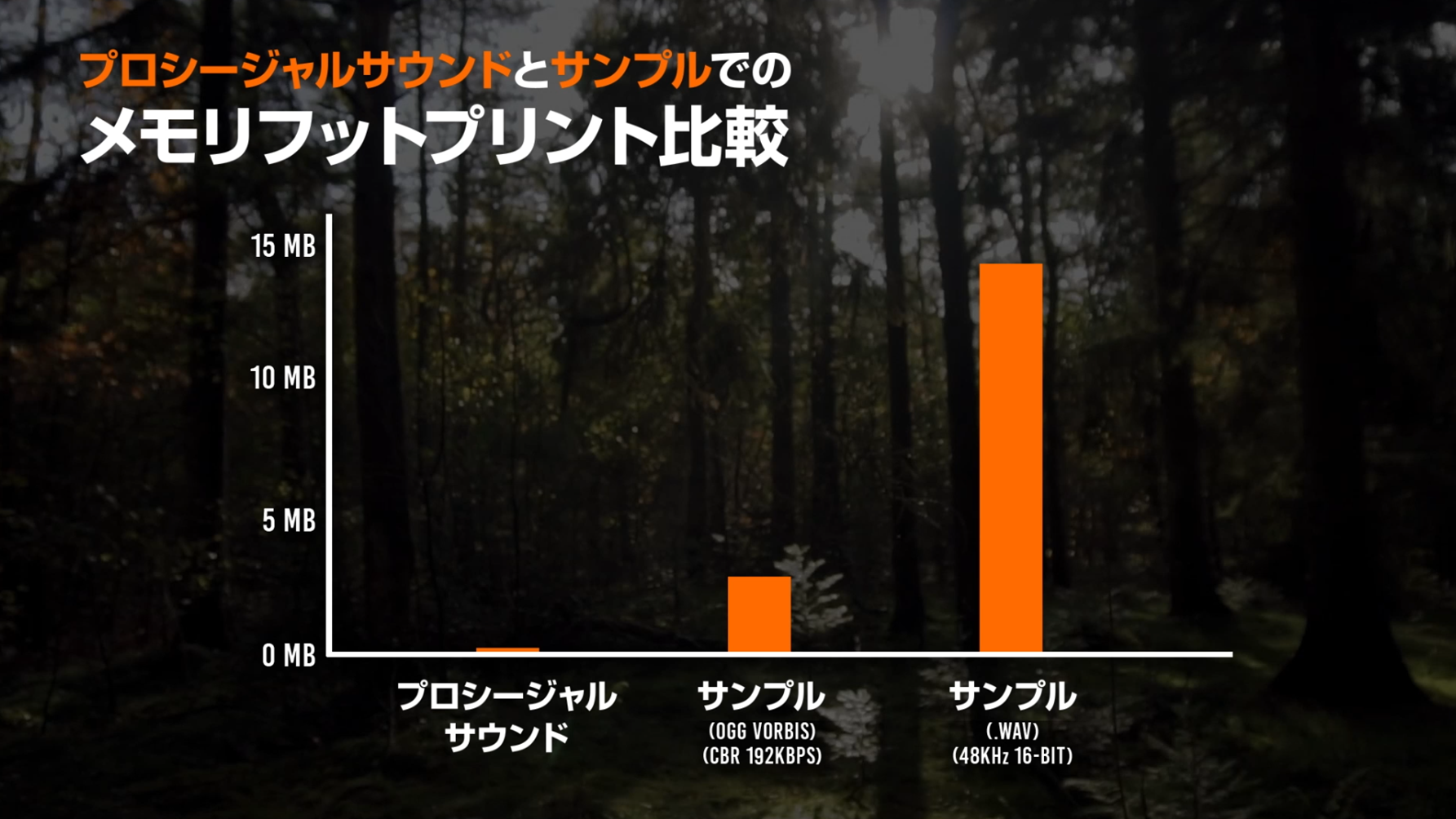
より高速なアクセス
たとえばARなど、何が起こるかを予測することが不可能、あるいは可能性が多すぎる場合、すぐに適切なコンテンツを取得することは非常に困難です。必要になりそうなすべてのサンプルをメモリに格納、あるいはサーバーから時間内にアクセスできると仮定するのは現実的ではありません。
プロシージャルオーディオモデルのメモリフットプリントは非常に小さいため、より多くのデータをメモリに格納でき、より高速に転送できます。また前述のように、各モデルは多くのバリエーションを生成できるため、そもそもそれほど多くのメモリを必要としません。
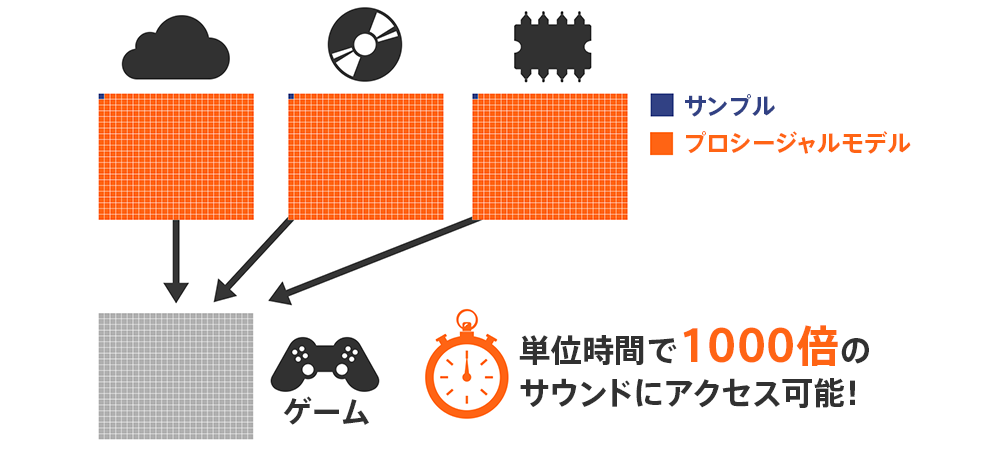
他にも音の品質がよいなど、メタバースや複合現実に限らず、固定録音よりもプロシージャルサウンドを使用する方が多くのメリットがあります。たとえばサウンドはゼロから生成されるため、バックグラウンドノイズがなく、可能な限り最高のダイナミックレンジが得られます。
プロシージャルオーディオのVR、ARへの活用にご興味がありましたら、当社のソリューションとサービスもご覧ください。
お客様のニーズに沿ったエンジンやツールの開発、没入型体験のためのプロシージャルサウンドモデルを設計するお手伝いをいたします。
