











Traditional sample-based solutions are ill-suited to create highly interactive audio content for the Metaverse and Mixed Realities in general. In this post, we go through some of the challenges these new types of experiences present, and we examine how procedural audio is the best solution to meet them.
Although sound spatialization has rightly received a lot of attention, sound generation for the Metaverse is still very much in its infancy, and hardly mentioned. However, because procedural sound effects are generated in real-time based on a model and a set of parameters (instead of using pre-recorded samples), they offer many advantages for audio in the Metaverse, in the same way rendering 3D objects is far more flexible to create immersive environments than displaying still pictures.
Explosion of Content
The amount of audio content required to generate an immersive experience is staggering, even in a limited environment. During the procedural audio panel at AVAR 2022, Scott Selfon from Meta described an experiment where the sound design team had to evaluate the number of sounds they would have to create to satisfyingly simulate a ping pong ball during a game – such as hits on the table and walls etc… – and the result was no less than 250 sounds!
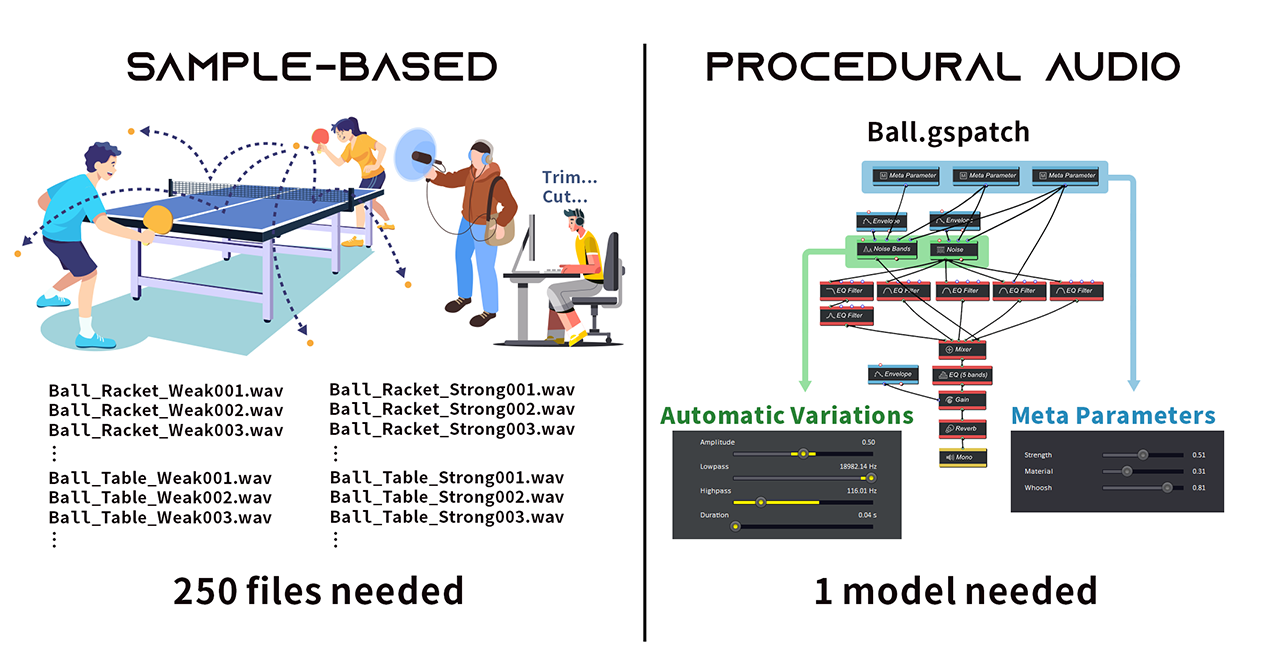
Procedural audio allows, simply by adjusting model settings and taking into account real-time input parameters – possibly physically informed – to generate all these sounds with just a few models. This is also a huge time and money saver, as there is no need to source new sounds, to record the missing Foley, or to edit existing samples for each minor change to a project.
Variations
Not only are different sounds needed, but variations of these sounds are required to avoid repetitiveness, and breaking the sense of immersion. By slightly randomizing the parameters of a procedural audio model, sound variations can be automatically generated (for example to get a slightly different footstep, whoosh, or gunshot each time the sound is triggered).

Creating variations with a sample-based audio system is far more limited as there is no control over the production of the sound itself, and modifications can only be applied as post-processing such as increasing / decreasing the volume, applying a filter, pitch-shifting etc..
Higher Interactivity
Mixed realities and the Metaverse allow users to interact with objects, e.g., bending a stick, breaking it, hitting a surface with it, and so on. As mentioned above, the original samples can only marginally be transformed as there is no control on their generation.
Procedural audio models allow for a higher degree of interactivity by adjusting both the model settings and the input parameters, which may act as various excitation signals, for example in the case of physics-based interactions.

Using a model, new sound data can be generated for as long as an action lasts, without any repetition. To do the same, a sample-based system will typically need to time-stretch a recorded sound (with a potential loss in audio quality) or to loop it, creating repetition, and requiring longer samples.
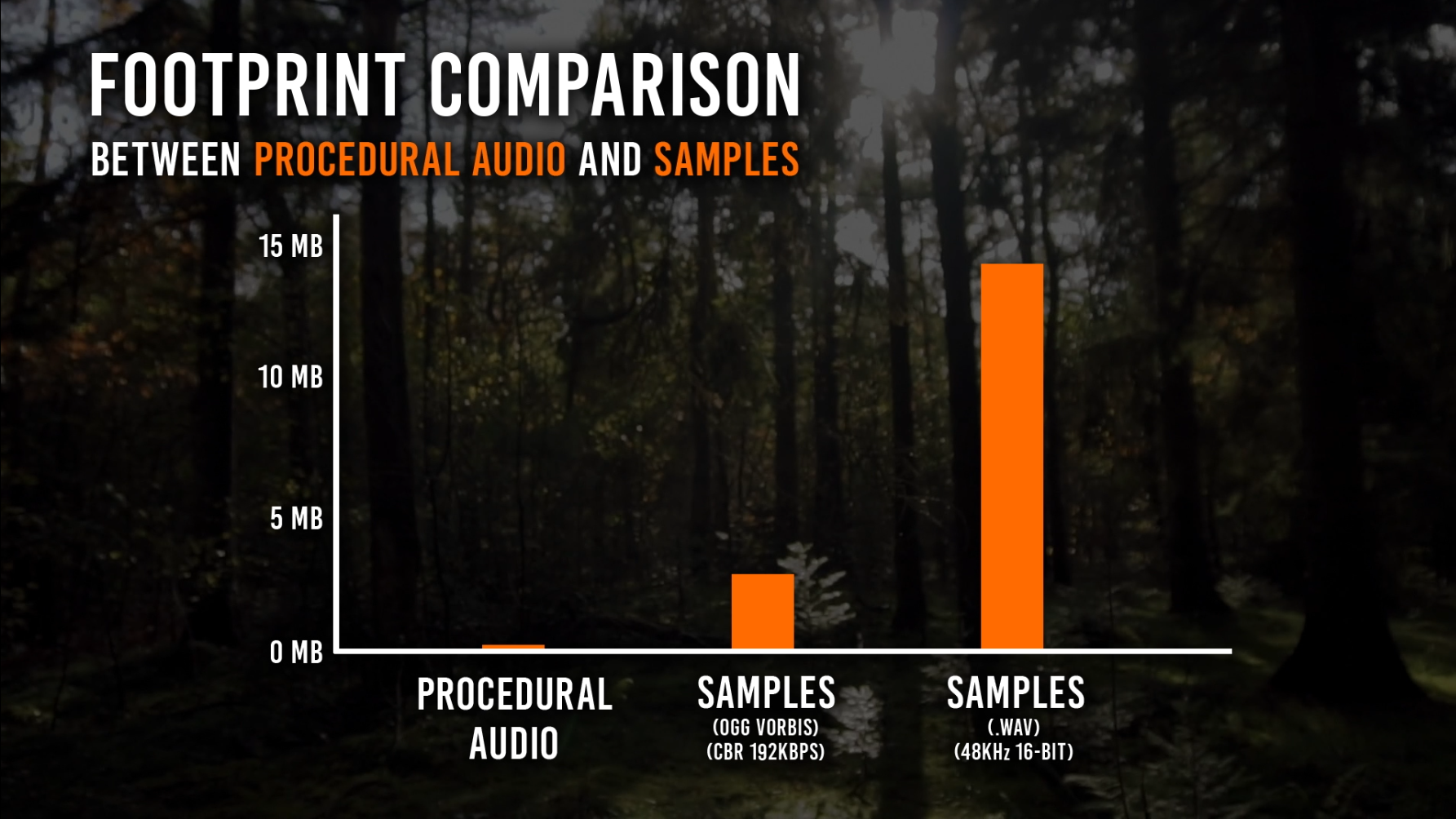
Smaller Footprint
Open world experiences require large collections of samples to cover all possible scenarios. This is amplified in the case of AR where virtually anything can happen. As only the parameters of the models need to be stored – and not the audio data – the memory and disk footprint of procedural audio are orders or magnitude lower than for audio recordings. This is a huge benefit, especially when developing for mobile platforms.
Faster Access
Getting the right content at a moment notice is a lot more difficult when predicting what will happen next is either impossible (for example in AR), or if there are too many possibilities. It is unrealistic to assume that all the potentially required samples can be stored in memory, or can be accessed in time from a server.
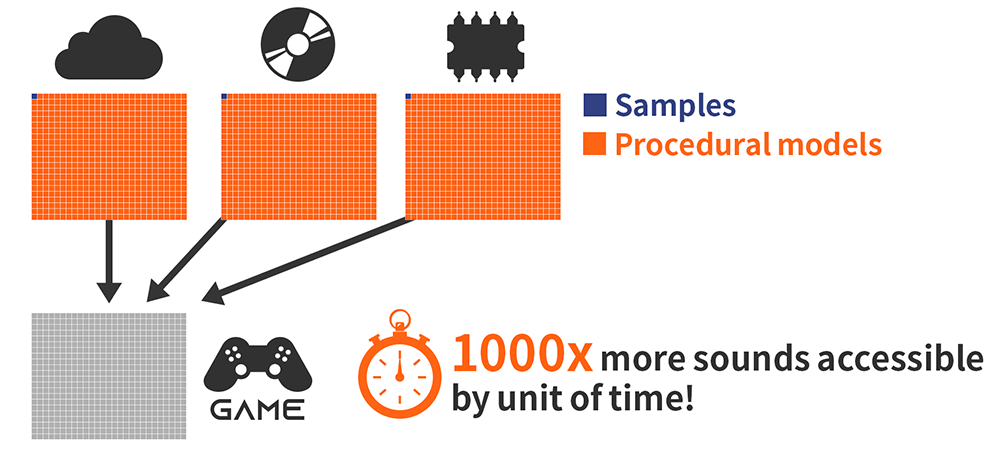
Because of the drastically lower memory footprint of procedural audio models, more can be stored in memory and they can be transferred faster from a server. In addition, since each model can generate many variations, fewer are needed in the first place.
There are many more general benefits from using procedural audio over fixed recordings which are not limited to the Metaverse and mixed realities, such as optimal audio quality. Indeed, since the sounds are generated from scratch, they have no background noise and offer the highest dynamic range possible.
If you are interested in leveraging the benefits of procedural audio for your virtual or augmented environment, feel free to check out our solutions and services. We can help you evaluate your needs, and develop engines and tools, as well as design procedural audio models for your immersive experiences.
